Design Principles
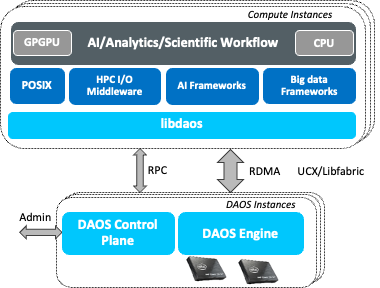
DAOS is unique by its design and is the result of 12 years of R&D between 2012 and 2024. The baseline DAOS interface is a high-performance scalable key-value-array store supported by the libdaos library over which many data models (e.g. POSIX namespaces, HDF5 datasets, python) have been implemented. Data is stored on remote engines running on storage nodes that are aggregated to form a DAOS system that provides a global namespace to access datasets.
DAOS is built on the following principles:
- No synchronous read-modify-write
- No locking
- No client tracking or client recovery
- No kernel code
- No vendor lock-in
- No centralized metadata server
- No data inconsistencies
- Versioned Byte-granular I/Os
- Multi-version concurrency control
- Data persistent on I/O completion
- End-to-end in user space
- Built on open-source software
- Distributed key-value-array store
- Serializable distributed transactions
Versioning is at the heart of DAOS. System membership and even every I/O operation are tagged with a version called an epoch. The DAOS design has been influenced by experience with the Lustre filesystem, databases like Google Spanner and techniques used in high-performance communication middleware like MPI.
Multi-tenant Storage Pooling
DAOS pools are fat-provisioned storage reservations managed by the system administrator. A pool can span all or a subset of the engines to deliver more capacity and performance. Fine-grained Access Control List (ACL) can be set on a pool.
Pools can be used to cover several different use cases:
- Single persistent pool covering all the space for simplicity.
- One pool per project with fine-grained access control for each project member.
- An ephemeral pool created for each job by the batch manager providing isolation like a burst buffer.

Datasets as First-class Citizen
DAOS unwinds 30+ years of file-based management and supports the notion of datasets natively. Datasets are called containers in DAOS and are managed by the user. They are the basic unit of storage and can be snapshotted. This effectively means that DAOS offers the end users the ability to manage snapshots. A DAOS container has a type to identify the data model it stores (e.g. a POSIX namespace, a collection of python objects).
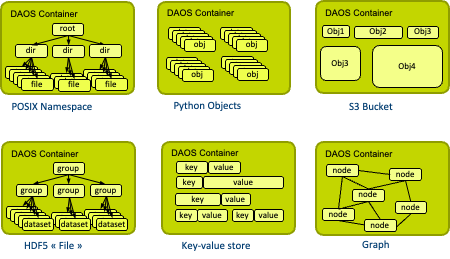
Unlike pools, DAOS containers are thin-provisioned and share the space from the pool they belong to. A POSIX container can have trillions of files or directories and petabytes of data. Fine-grained access control similar to NFSv4 ACL can be set on individual DAOS containers.
Instead of managing a random collection of files, DAOS users manage dataset and are provided with an advanced container query interface. Managing billions or trillions of files has just become simple!
Unmatched Performance
As demonstrated in the IO500 challenge, DAOS delivers a level of performance which is orders of magnitude higher than other options. This is the only storage system that can deliver a read latency below 20μs and more than 1M IOPS per storage node. The engine is built on an asynchronous model using futures & promises programming and can support very deep queue depth with minimal hardware resources.
Filesystem data (i.e. files) and metadata (i.e. directories) are distributed on all the engines by virtue of the underlying key-value-array interface which is fully distributed and declustered by design.
Thanks to a flexible network stack, DAOS can run over either libfabric or UCX and leverage RDMA capabilities whenever available. This allows DAOS to operate on a wide range of fabrics including Ethernet, RoCE, Infiniband, OmniPath and Slingshot.
Data Protection with Self Healing
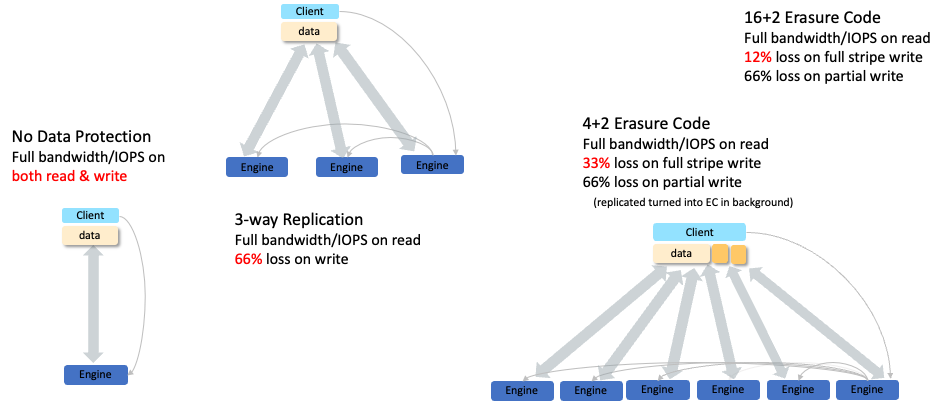
DAOS supports a wide range of data protection schemes. DAOS objects can be either erasure coded, replicated or have no data protection. Pretty much any Reed-Solomon erasure codes are supported, although DAOS is validated with 2+1, 2+2, 4+1, 4+2, 8+1, 8+2, 16+1 and 16+2. Similarly, an object can be replicated N-way.
This flexibility does not trade simplicity. While users have the opportunity to fine-tune the data protection scheme for each file/directory/object, this can also be set at the dataset level via the redundancy factor parameter. DAOS will then automatically select the most appropriate redundancy schema depending on the type of objects stored in the dataset.
As mentioned before, DAOS does not do any read-modify-write operations from the client to avoid false sharing issues and spurious contention between concurrent clients accessing the same object. When erasure coding, it means that a full-stripe write is encoded on the client. Small I/Os to an erasure-coded object are replicated on the engines and then turned into erasure code in the background. The diagram below summarizes the performance impact of enabling erasure code.
DAOS engines monitor each other constantly via a SWIM algorithm. When an engine becomes unresponsive, it is excluded from the system and self-healing is triggered to restore redundancy on the surviving engines. Objects are declustered across all the engines which guarantee a lightning fast rebuild involving all the surviving engines.
Once repaired, the excluded engine can be reintegrated into the system. If the storage media attached to the excluded engine was not damaged (e.g. no SSD replacement), DAOS will rebuild incrementally only the changes that were made to the impacted objects while the engine was excluded. This capability causes temporary exclusions (e.g. short network outage) to be managed smoothly without transferring a huge amount of data over the network upon reintegration.
In cloud environments, restoring redundancy on the surviving engines is not necessarily the best approach since new storage instances can usually be spun up in the blink of an eye. Therefore, DAOS supports a feature called delayed rebuild where the system waits for a new instance to be added to the system after an engine exclusion to trigger a rebuild.
Rich Software Ecosystem
DAOS has rich open-source client ecosystem built over libdaos. libdfs is the library implementing a POSIX namespace (i.e. files) over libdaos. The beauty is in the details and it is worth noting that there is no POSIX-specific code executed on the engines which only handle key-value-array store operations.

For more information about the client ecosystem, please refer to the DAOS user guide.